


Traveling Salesman Problem (외판원 문제)
v1 개정 2025.02.03


외판원 문제(Traveling Salesman Problem; TSP)는 컴퓨터 과학 및 수학 분야에서 잘 알려진 조합 최적화 문제입니다. 이 문제의 핵심은 주어진 각 도시(노드)를 정확히 한 번만 방문하고 시작 도시로 돌아가는 가능한 최단 경로를 찾는 것입니다. 이때, A도시에서 B도시로 가는 거리(d)는 가중치가 존재합니다. 문제의 경우에 따라서 시작점으로 돌아가지 않을 수도 있는데, 이 제약 조건이 없다고 해도 계산 복잡도는 변하지 않습니다.
어쨌든 TSP는 대표적인 NP-난해(NP-hard) 문제로 모든 문제에 대해서 다항식 시간에 해결할 수 있는 알려진 알고리즘은 없습니다. 대신 작은 N의 경우(일반적으로 N ≤ 16)에는 분기한정법(Branch and Bound; B&B; 가지치기)이나 DP로 풀 수 있습니다. 또, N이 큰 경우에는 1.5의 근사비를 가지는 크리스토피데스 알고리즘과 같은 근사 알고리즘으로 풀 수 있습니다.
외판원 문제는 택배 기사님들의 효율적인 방문 순서나 회로 기판를 만드는 기계의 효율적인 이동과 같이 현실에서 적용될 수 있습니다. 이러한 경우 N의 크기가 커질 수 있기 때문에 근사 알고리즘을 사용합니다. 정확한 답은 아니더라도 결과를 빠르게 낼 수 있다면 택배 기사님들이 한 두번 비효율적인 경로로 가시더라도 화내시지는 않겠죠?
외판원 순회의 일반적인 문제를 가지고 한번 개선해 가면서 문제를 풀어보겠습니다. 풀 문제는 다음과 같습니다. 외판원 순회(백준 2098)
N = 5일 때 최소 거리를 찾는 과정 (완전탐색)
위의 그림과 같이 1 - 5까지 5개 도시가 있고 가중치가 있는 간선으로 이어져 있을 때, 사이클이 있는 최단 경로를 찾기 위해서 먼저 모든 가능한 경로를 구하고 그 중 길이의 최소값만을 택하는 방법을 생각할 수 있습니다. 완전탐색이죠. 가장 확실한 방법이지만, 그만큼 시간복잡도가 큰 방법입니다. 도시의 수가 N개로 늘어나면 시간복잡도는 O(N!)이 됩니다. N = 10일 때 경우의 수는 약 36만 가지, N = 11일 때 경우의 수는 약 4천만 가지입니다.
어쨌든 모든 경우의 수를 탐색하기 위해서는 dfs가 적절할 것으로 보입니다. 코드를 작성하면 다음과 같습니다.
코드는 가중치를 저장하기 위한 weight, 최종 답을 저장하기 위한 answer, 그리고 모든 경우의 수를 탐색하기 위한 dfs() 메서드로 단순하게 구성되었습니다.
비트마스킹이 어려운 분들을 위해 visited를 간단히 설명하면 다음과 같습니다.
•
N = 4인 도시들 중에서 visited = 1011₂이라면
임의의 도시를 갔다/안갔다만 구분할 수 있으면 되기 때문에, 위와 같이 표현하면 정수 하나로 각 도시 방문 상태를 나타낼 수 있습니다.
이 완전탐색 풀이는 N ≤ 10정도로 경우의 수가 작을 때만 사용할 수 있는 방법입니다.
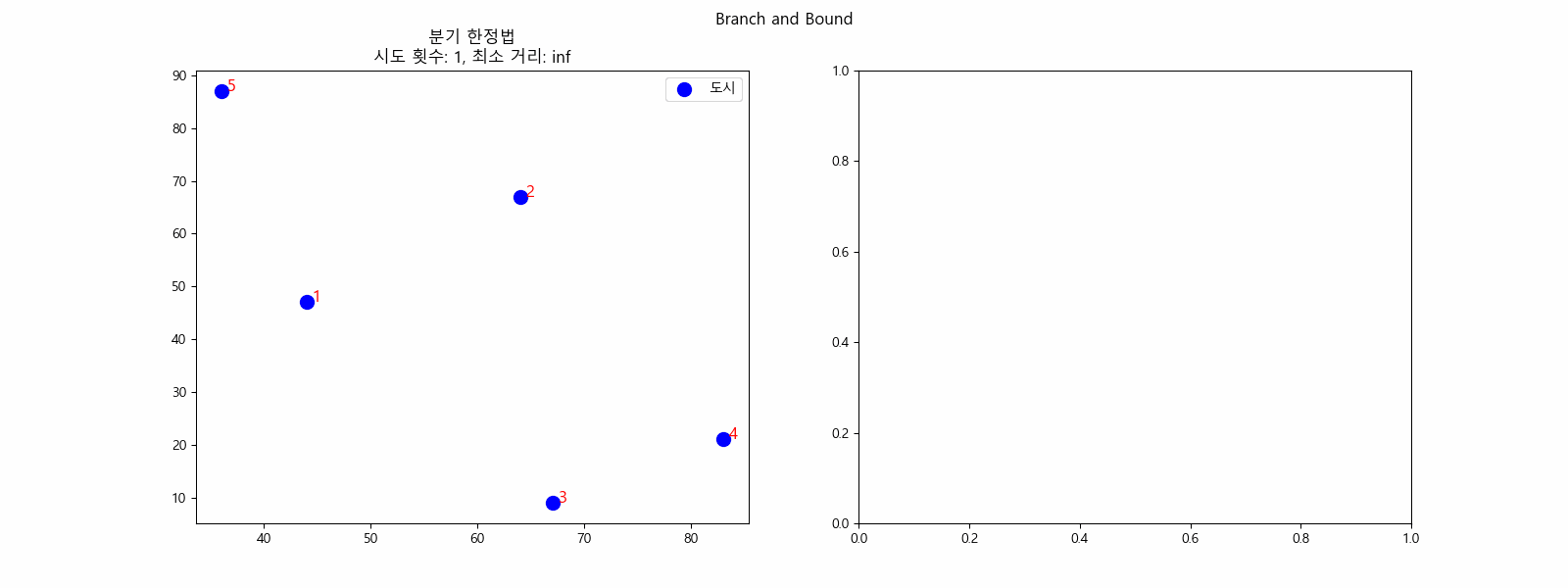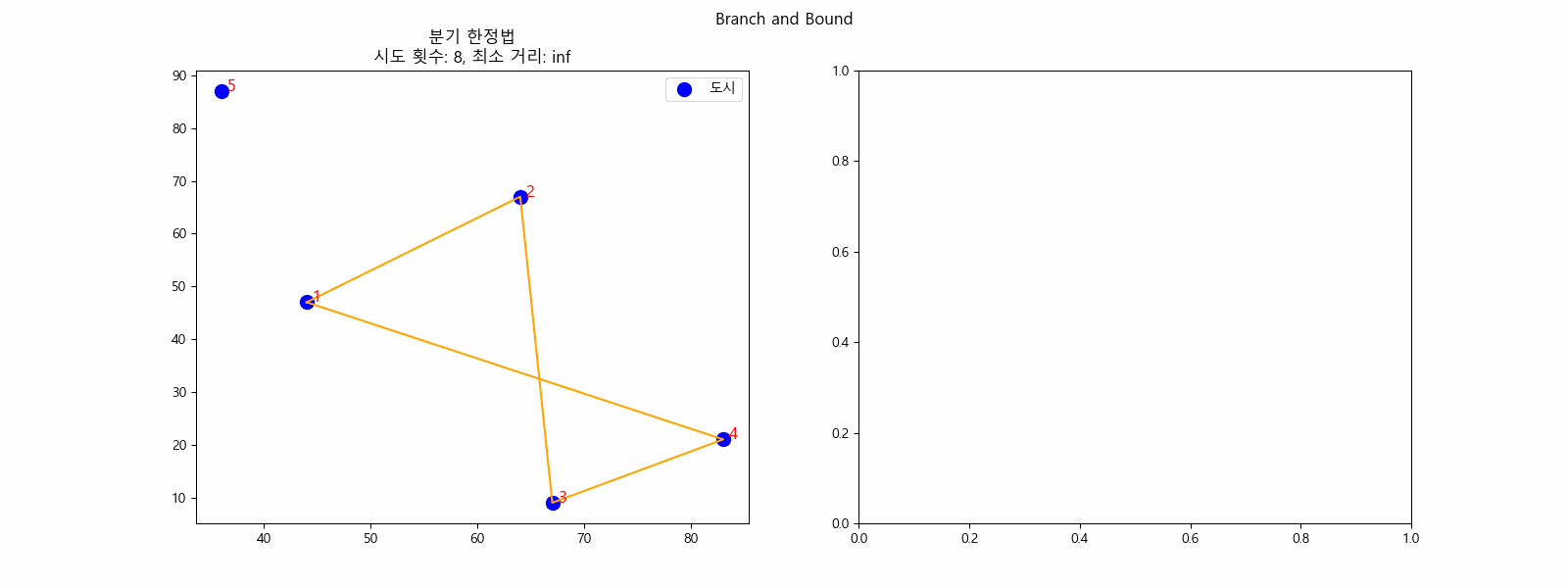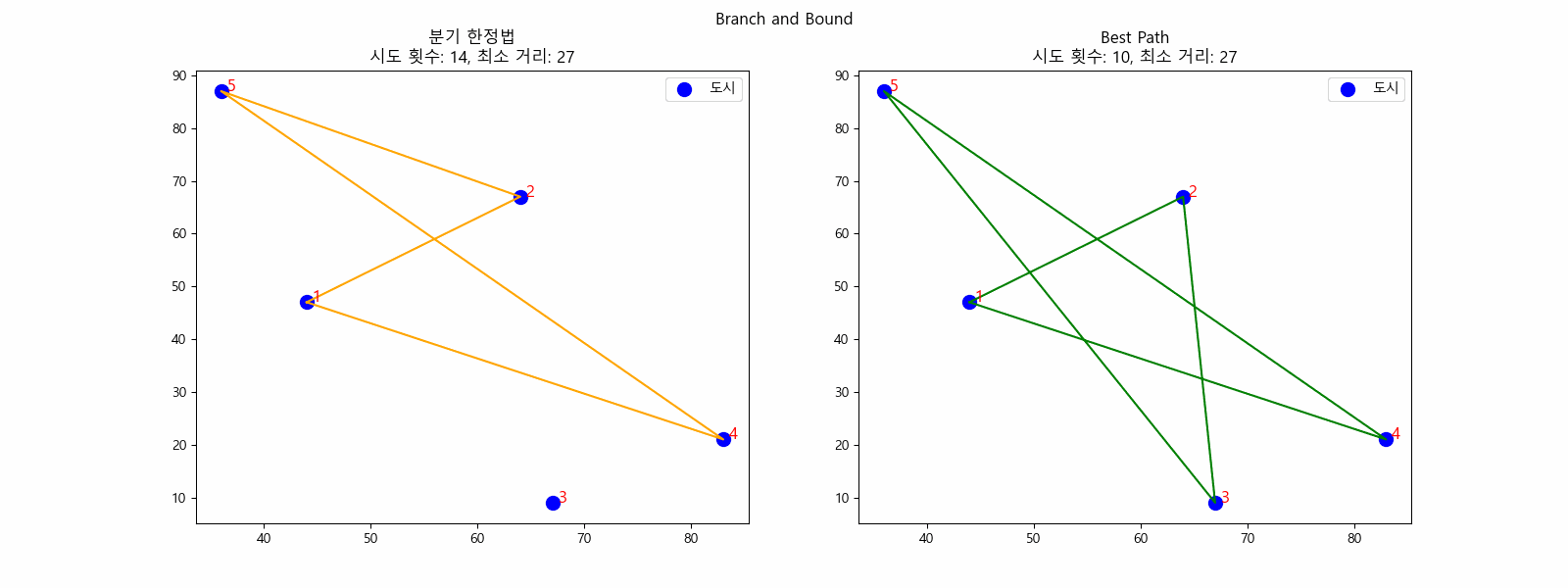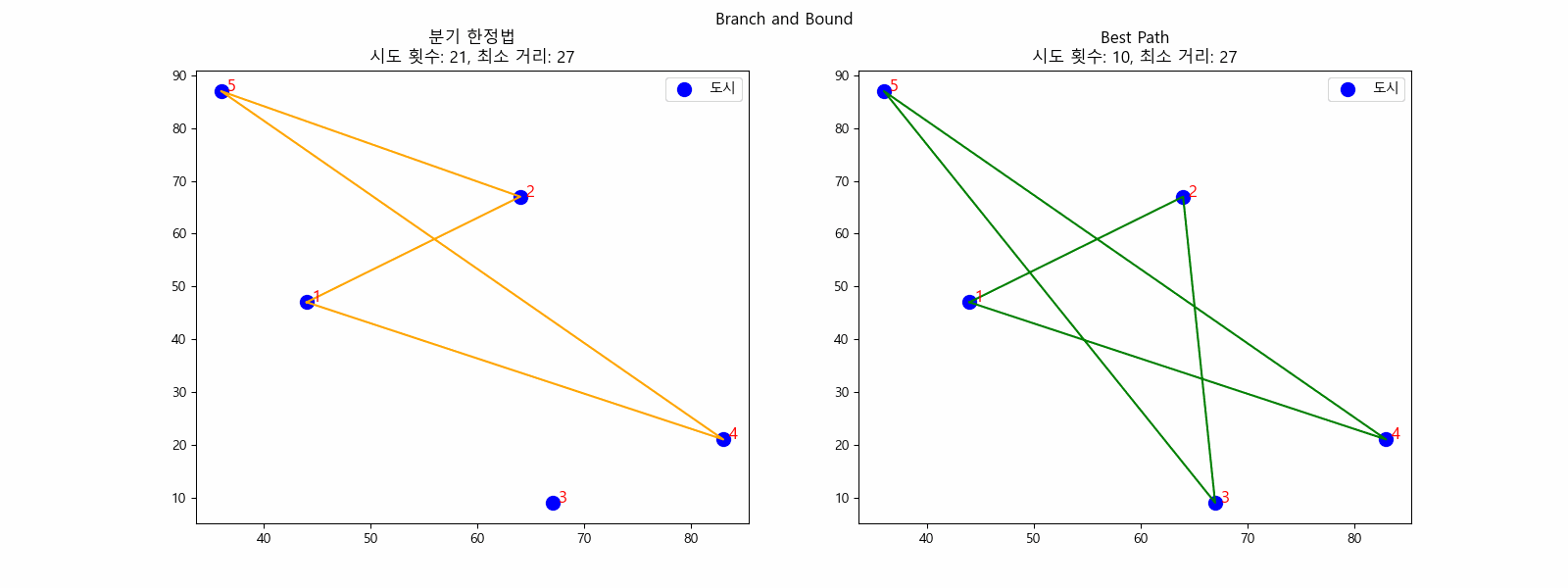
N = 5일때 최소 거리를 찾는 과정(분기 한정법)
앞서 모든 경우의 수를 전부 찾아서 최적의 결과를 찾는 완전탐색은 N이 충분히 작을 경우에만 적용 가능한 한계가 있었습니다. 이 방식을 개선하려면 도시를 탐색할 때 굳이 모든 경로를 가보지 않으면 될 것 같습니다. 임의의 도시에서 다음 방문할 도시를 결정할 때, 어느 경로가 가망이 없는지 미리 알아두고 그 도시는 방문할 후보에서 제외한다면 훨씬 효율적이겠죠. 여기서 분기 한정법이 사용됩니다.
분기 한정법은 모든 후보를 놓고 최적화 할 수치의 상한 혹은 하한 경계(Bound)를 추정해 가망이 없는 경로, 즉 최적의 답으로 이어질 수 없는 경로를 가지치기(Pruning)해 나가는 방법입니다. 제거한 경로에서 파생되는 경로를 살펴보지 않으므로 불필요한 시간 소모를 줄일 수 있습니다.
외판원 순회 문제에서는 전체 이동 거리가 가장 짧은 경로를 찾는 것이 목표입니다. 따라서 하한 경계를 추정해야 합니다. 하한 경계는 해당 경로가 실제로 존재하지 않더라도 경로에 대해서 이론적으로 가능한 최소값을 제공합니다.
예를 들어 이미 몇 개의 경로를 살펴본 후 거리가 30인 경로를 찾았다고 생각할게요. 하지만 확실한 답을 찾으려면 또 다른 경로를 살펴봐야 합니다. 이때 살펴볼 경로의 하한 경계가 35라면(아직은 방문해서 실제 이동 거리가 얼마나 되는지, 경로가 있긴 한건지 확인하진 않았지만 이 경로는 최소한 35 이상의 값을 가진다는 것을 안다면) 굳이 가볼 필요가 없겠죠? 이렇게 하면 불필요한 계산을 방지하고 최적의 솔루션을 찾는 속도가 빨라질 수 있습니다.
이제 실제 가중치가 있는 예제를 가지고 분기 한정법에 따라 하한 경계를 구하고, 문제를 풀어봅시다.


각각의 도시로 가는 경로의 길이
1번 도시에서 자기 자신을 제외하고 다른 도시로 가는 최소 거리는 3번 도시로 가는 4입니다. 그리고 2번 도시에서 자기 자신을 제외하고 다른 도시로 가는 최소 거리는 3번 혹은 5번 도시인 7입니다. 이렇게 각 도시에서 갈 수 있는 최소 경로를 모두 더하면 4 + 7 + 4 + 2 + 4 = 21이 됩니다. 어떤 경로라도 이 경로보다는 최소한 길겠죠. 이것이 초기 하한(lower bound)입니다.
이제 분기 한정법에서는 우선순위 큐(Priority Queue)를 사용해서 하한이 가장 낮은 순서대로 가능한 경로를 탐색하기 시작합니다. 과정은 다음 그림과 같습니다.


상태 공간 트리 (State-Space Tree)
1.
초기 1번 도시에서 시작합니다. 이 노드를 Node 1이라고 하겠습니다. Node 1에서 갈 수 있는 2, 3, 4, 5번 도시의 bound를 각각 구합니다. 초기 하한이 21이었으니 2번 도시를 방문한다면 bound는 (초기 하한) - (1번 도시에서 갈 수 있는 최소 경로) + (1번 도시에서 2번 도시로 가는 경로)가 되겠네요. 즉, 21 - 4 + 14 = 31입니다. 이처럼 bound를 구하면 가장 정답이 될 가능성이 높은 건 bound가 22인 3번 도시를 방문하는 경우겠네요. 우선순위 큐에 모든 노드를 저장한다면 다음으로 방문하는 건 3번 도시입니다. 이를 Node 2 라고 하겠습니다.
2.
이러한 과정을 반복합니다. 그럼 최종적으로 Node 3에서 마지막 도시인 4, 5번 도시를 각각 방문하면 length를 산출할 수 있습니다. 이 때 가장 짧은 length는 1-3-2-5 도시 순서로 방문하는 31입니다. 이 length는 정답이 될 수 있는 후보로, 가지치기를 하기 위한 중요한 정보입니다
3.
다음으로 가장 작은 bound인 Node 4 를 탐색하고 2번 도시, 5번 도시를 방문해 length를 산출합니다. 43, 34로 현재까지는 31이 정답 후보입니다.
4.
다음으로 가장 작은 bound인 Node 5 를 탐색합니다. 정답 후보가 아직 31이기 때문에 유망한 노드입니다. 4번 도시에서 2, 3, 5번 도시로 갔을 때 bound를 계산하면 각각 45, 38, 30입니다. 45, 38은 이미 정답 후보인 31보다 크기 때문에 가망이 없습니다. 제외합니다. 5번 도시로 가는 Node 6 로 갑니다.
5.
Node 6 에서 2번 도시를 방문했을 때 기존 정답 후보보다 작은 30이 나왔습니다. 업데이트합니다.
6.
다음으로 우선순위 큐에서 Node 7 , Node 8 , Node 9 를 뽑지만 전부 정답 후보인 30보다 bound가 커서 가망이 없습니다.
7.
최종적으로 정답 후보인 30이 정답이 됩니다.
이처럼 정답 후보보다 큰 bound를 가진 노드를 가지치기해 그 노드에서 파생되는 경로를 가지 않음으로써 시간 소모를 줄이는 방법입니다. 모든 경우의 수를 전부 탐색하는 완전탐색보다 확실히 효율적인 방법이죠? 코드로 보면 다음과 같습니다.
상태 공간 트리의 상태를 관리할 Node 클래스를 정의합니다. 이 클래스는 현재 어느 도시에 있는지 currentCity , 몇 개의 도시를 방문한 상태인지 level, 어떤 도시들을 방문한 상태인지 visited , 현 상황에서 계산한 하한 경계 bound, 그리고 현재까지 지나온 길을 다 더한 length 의 상태들을 관리합니다.
다음으로 분기한정법 로직을 수행하는 branchAndBound() 메서드를 봅시다. 가장 먼저 우선순위 큐를 초기화하고, 시작 위치에서 하한 경계를 계산하기 위해 getInitialBound() 메서드를 호출해 initialBound 를 계산합니다. 로직은 단순히 이중반복문을 통해 각 도시에서 다른 도시로 갈 때 최소 경로를 찾아서 모두 더한 뒤 리턴합니다.
그리고 이 정보를 바탕으로 Node 인스턴스를 만들어 우선순위 큐에 집어넣은 후 반복적으로 호출하면서 bound가 가장 낮은 Node부터 계산합니다.
이 때, Node의 bound가 이미 정답 후보인 answer 보다 크다면(node.bound > answer) 제외해야겠죠.
이처럼 가망이 없는 경로를 가지치기해 시간을 절약하는 장점에도 불구하고, 분기 한정법은 N이 클수록 계산량이 급증할 수 있습니다. 또, 절대 답이 될 수 없는 가지를 쳐내는 것에 불과하기 때문에 실제로 얼마나 시간이 절약될지 장담할 수 없고, 우선순위 큐에 저장해야 할 노드의 수도 늘기 때문에 공간적으로도 불리해질 수 있습니다.
그렇다면 왜 알아야 할까요? 그건 이후 TSP를 근사해서 풀기 위한 방식의 기초가 되기 때문입니다.
어쨌거나 분기 한정법으로는 예시 문제인 백준의 외판원 순회 문제를 풀기 힘듭니다. 조건이 N ≤ 16이므로 시간적, 공간적으로 확정적인 방법이 아니면 힘들겠네요. 그래서 동적 프로그래밍으로 풉니다.
동적 프로그래밍은 큰 문제를 작게 나누어 재귀적으로 풀고, 이미 계산된 결과를 저장해두어 중복 계산을 줄이는 방법입니다. 특히 이러한 최적화 문제를 풀 때 유용해요.
외판원 문제에서 동적 프로그래밍은 메모이제이션(Memoization) 기법과 함께 사용됩니다. 이 방법에서는 모든 경로를 탐색하지 않고, 현재까지 방문한 도시의 집합과 마지막으로 방문한 도시를 기준으로 최적의 경로를 계산합니다.












